
I look at digital data all day and often take for granted how good I’ve got it. When running an analysis on the impact of a marketing campaign or an A/B test, there are hundreds of thousands of data points at my fingertips just waiting for me to extract meaning and take action.
The beauty of digital analytics is that you can actually look at how data is collected in real time.

Think about that for a second: if you’re doing analysis within a data warehouse you may have no idea, or visibility, into where that data is actually coming from or how it is collected. Digital analytics is different – I can actually go to a site, pull up a packet sniffer and watch as information is collected and sent off to tools we use every day like Google Analytics, Adobe’s Marketing Cloud or DoubleClick.
I firmly believe that having a fundamental understanding of how your data is collected will make you a better analyst – one of Cardinal Path’s core beliefs is “To understand data, you must engage in the world” and this is a perfect example of that coming to life. Problem is, there’s a lot going on behind the scenes to make the reports you see in the tools we use every day possible. I’m going to break it all down and hopefully shine a light on how it all works.
A note before we begin, I’m simplifying a lot below. The way Facebook collects data is different from Google Analytics which is different from Adobe but all of these tools are still relying on a similar methodology.
Let’s start with the browser
When you type a URL into your address bar your browser requests that page from a web server. Once the page is returned your browser then begins to execute the code that lives on the page (press crtl+u right now to check this page’s code out). The page’s HTML, CSS, JavaScript, etc. all start to interact with each other and before you know it you’re looking at a fully rendered page. As your browser loads a page it is making hundreds, and sometimes thousands, of requests for information from web servers: things like images, fonts, style sheets and videos all need to be loaded onto the screen.
To see this in action, load a web page and launch your development tools (in Chrome right click on the page and then click “Inspect”). Then click in the network panel tab, refresh the page and you’ll see something like this:
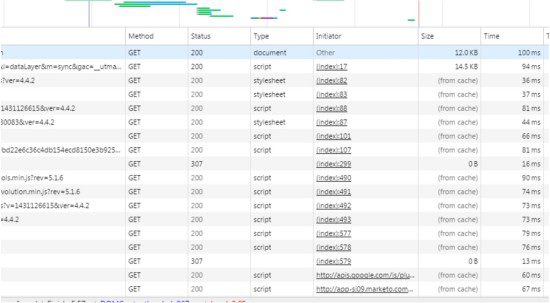
What you see are all the requests for information that are being made by the code on the page, the order in which these requests are made, what was returned, and how long it took to return that information from the web server back to the browser.
Tagging a website
Digital data collection is often referred to as tagging. The most common form of tagging comes through the use of JavaScript to collect information about the page or actions taken on the page and then send that to a third party tool that processes that data and make it ready for analysis. As a page loads the JavaScript placed on the page will grab information from the page, the user, their cookies, etc. and package that all together and send it over to a data collection server. This process is called “firing a tag” or “sending a web beacon.”
Here’s what’s actually happening in your browser:
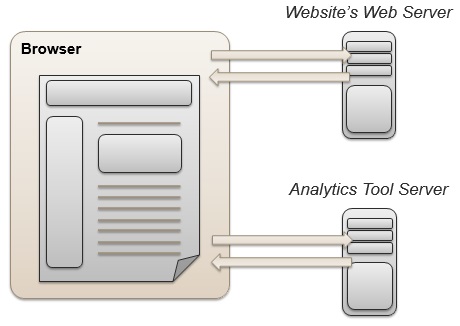
Data can be collected from multiple sources, the most common places we grab data from are:
- The HTTP headers – for things like browser information, referrer information, etc.
- On page code – often times we collect data from the page itself, things like a friendly name for the page, the section it belongs to on the site, etc.
- Cookies – see below
As mentioned above, the data is packaged into an image request and sent over to the web server of the tool that will be processing the data. Here’s an example of a Google Analytics request made on the CardinalPath.com home page:
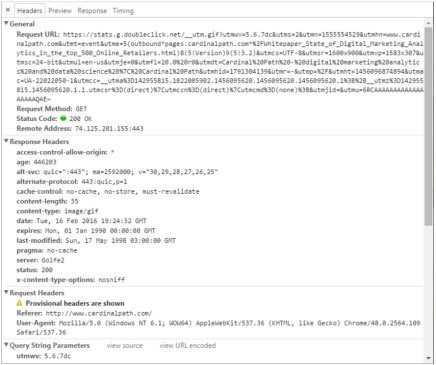
- Under general, you see the full URL being sent over to the server
- Everything after the ? in the Request URL is called the query string (see below)
- The response headers are what is returned from the data collection tool’s web server
- The request headers are the HTTP headers being sent over to the analytics tool
- These headers contain things like the page that referred the user to the current page they are on as well as the user agent, which is used to identify the browser, operating system, etc.
- The query string parameters are the different variables being sent over with the request; this is where all the information about the page, any custom dimensions, custom metrics, etc. are stored
When I debug tags on a website I rarely use the network panel though, there’s too much work involved. There are a few great tools that I like to use to help me see these requests quickly – two of my favorites are WASP and ObservePoint.
Cookies let us track across pages
Cookies are text files that lives within your browser. Often times they contain long alphanumeric strings that represent a visitorID. The web is often referred to as a “stateless” place – meaning that the server you’re requesting information from doesn’t know anything about you before or after that request is made. What I mean by that is when you request a page to be loaded in your browser the web server will send you all the information to load that page, but it won’t know what you’re doing on that page or even if you’ve navigated away (unless we explicitly tell it so).
Cookies are the bridge across pages as well as sessions. They allow us to tell a web server that the same browser that requested page A also requested page B. This is useful for keeping you logged into a website, or storing items within a shopping cart. Cookies also allow analytics tools to track what a visitor is doing across pages and sessions. You can view your own cookies in Chrome quite easily, just go here: chrome://settings/cookies and you can see their contents as well as expiration dates and what domains they’ve been set on.
First vs. Third Party Cookies
As mentioned above, all cookies are just text files that can be written and read by a web server or the code being executed on a website. When a cookie is written to your browser it is assigned a domain that can read the cookie. This is where we get the term first party and third party cookies from.
A first party cookie is written to the domain that you’re currently on, so in the case of www.cardinalpath.com first party cookies would be written to the domain of cardinalpath.com. A third party cookie is written to a domain different than the one you are currently on.
Here’s an example of the cookies being written when you arrive on CNN.com (to see this in Chrome right click and “Inspect” again, then navigate to the resources tab and expand the cookies menu).
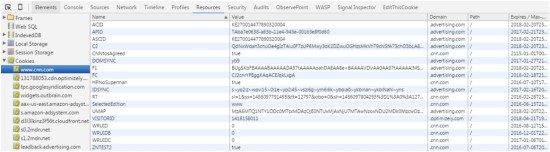
The domain of the cookie becomes important because it determines who can read the contents of the cookie. In the case of CNN, any cookies written to the domain of CNN.com are considered to be first party cookies – because the cookie domain matches the domain of the website the user is on. Where as a cookie written to advertising.com is considered a third party cookie because that domain is different from the current site the user is on. Third party cookies are useful to advertisers because their content can be read across domains, meaning whenever advertising.com code is loaded on any other website the user visits that code can read the value of that cookie.
It’s important to note that cookies cannot be read across domains, meaning code from CNN.com cannot read the values of the advertising.com cookies and the advartising.com cookies can’t read the CNN.com ones.
Privacy becomes critical
That brings us to probably the most important topic of digital data collection – privacy. As you can imagine, through the use of JavaScript and cookies a lot of information can be collected about a user as they browse the web. The goal of collecting this data is two fold: first is to make websites easier to use. Through deep analysis we can identify patterns of user behavior on a website to find the pages that work well and those that are giving people trouble. And then we can use this data to optimize those paths/pages to fix their problems.
The second goal here is to make advertising more effective. Using data to find what works, and does not, in paid search ads, banners, etc. and also using that data to serve more relevant, targeted ads.
All that said, privacy should be at the center of any data collection strategy. When doing analysis within tools like Google Analytics or Adobe Analytics the data is displayed in aggregate – because we’re looking for patterns over a large set of users and often not concerned about what an individual is doing on the site.
Additionally, we as an industry must strive to never collect and Personally Identifiable Information (PII). Things like email addresses, Twitter handles, etc. all should never be collected because they have the ability to reveal something personal about what should be an anonymous web user. Tools like Google Analytics have very strict PII policies that can result in the deletion of data and/or the deactivation of an account and trust me when I say this, they will delete your data if they find PII.
Want to learn more?
Now that you’ve got the basics of data collection down you may be wanting to learn more. If you’re intersted, sites like Code Academy and Code.org are great resources for learning the basics of JavaScript, HTML, CSS (as well as a whole lot more). If you do take classes here, I’d recommend starting with HTML, then going to CSS, jQuery and finally JavaScript for a basic understanding of web development.












